Is there a step-by-step manual to use PMD with our data.
As a first try, we assume the first step is to use the Canonicator to convert our data to Canonical JSON.
Is that correct?
We need help finding documentation illustrating how to use the Canonicator, and the whole PMD.
What would be the next steps?
1 „Gefällt mir“
I follow PMD’s guide by using Python scripts to convert the raw data (.csv) to what is called canonical JSON (.json) and then to a Turtle file (.ttl).
Example of a canonical JSON file of Heat treatment: JSON examples/exemplary-timeseries-bulkdata_Batch-3353.json · main · Ontologies / pmd-ontologies · GitLab
In the sample JSON file, the time series data is stored not in Triplestore but in MongoDB.
(https://forum.materialdigital.de/t/tripplestore-including-file-management/122)
In our case, the GlassDigital project, we don’t have so much and big time series data. I use a script to extract the desired time spans of each sub processes from the raw time series data. Considering that this is small time series data, I simply store this time series data as an array instead of a single value in canonical JSON. And then you could unpack the time series data after a SPARQL query and display/plot it as it was.
But if the time series data is quite big like the example of a canonical JSON file of Heat treatment, probably it’s better to store outside of triplestore. (it would be nice if someone shares their use case!)
For the usage of scripts for wrapping/mapping data, you could look at:
OntoPipe (rev02) - A PMD Demonstrator for Heat-Treatment Data Acquisition (Uploaded by: Henk Birkholz )A simple (stand-alone) demonstrator app based on a Heat-Treatment application ontology (HTAO) used for showcasing a pipeline from 1.) primary data in CSV format to 2.) homogenized data in JSON format to 3.) triples in Turtle format to 4.) named individuals instantiated in a graph database.
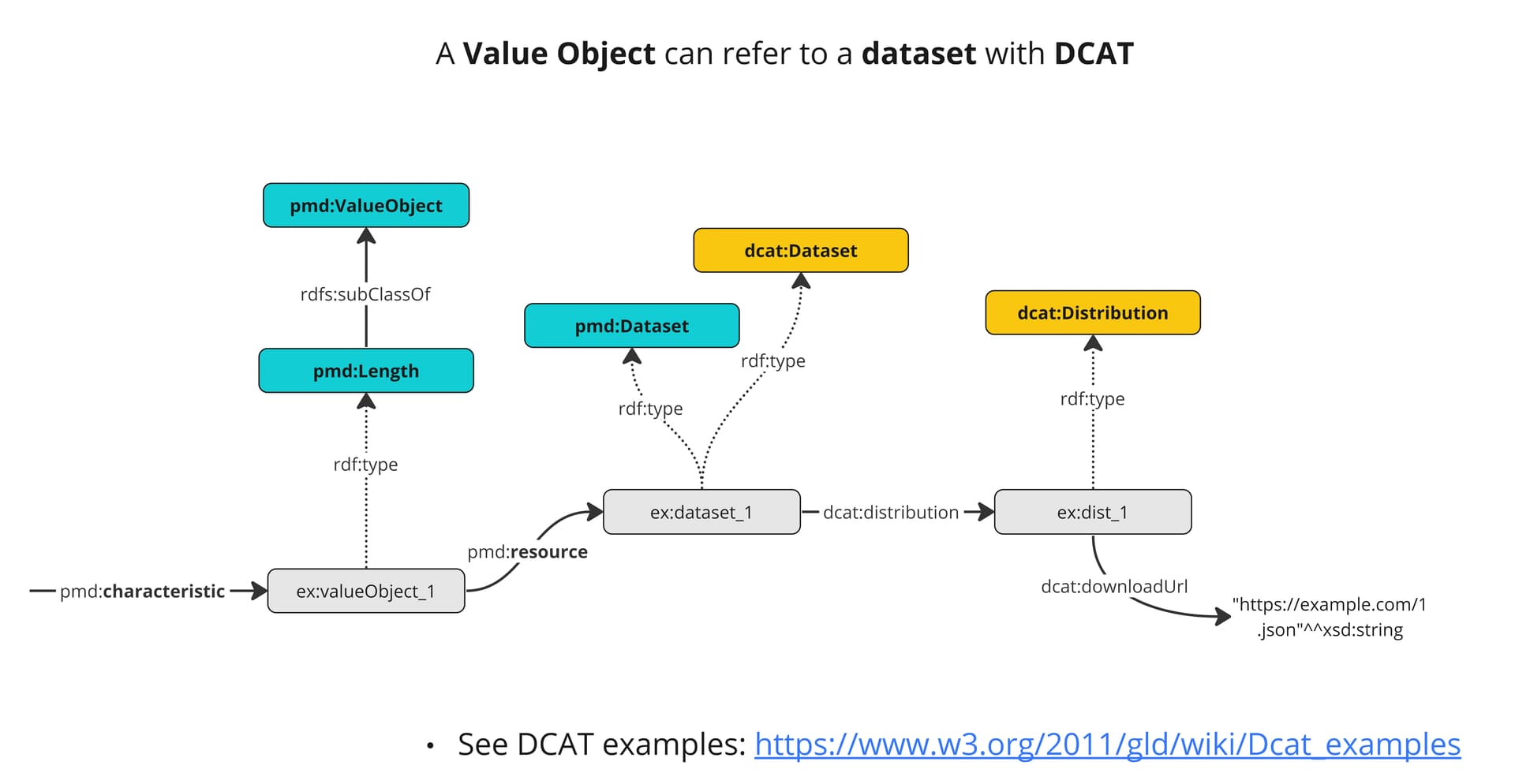
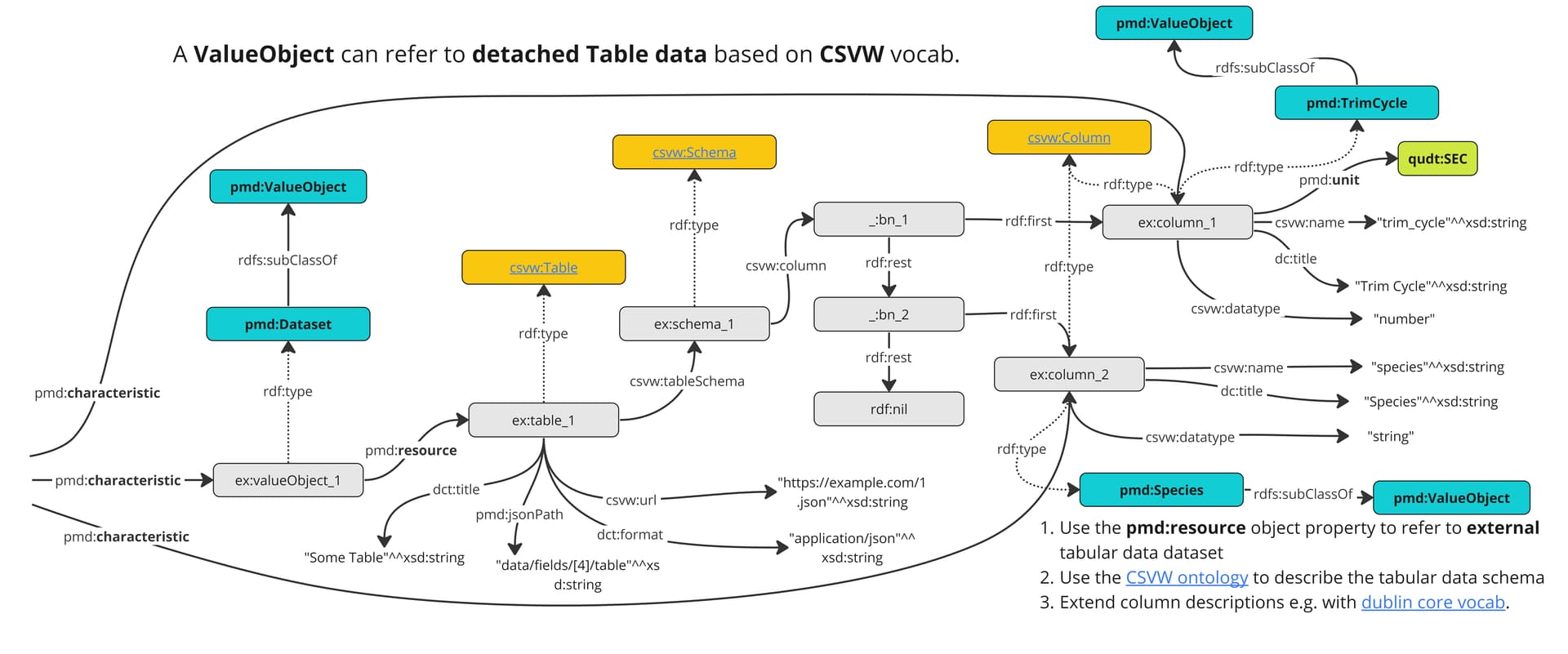
I suppose at the moment the best starting point is the Data Acquisition Pipeline, which should be accessible for PMD users at https://git.material-digital.de/apps/dap/. As for data series, to my knowledge, the current concept is to have the data series in the canonical json, but not add it to the a-box but rather have a URL in the a-box from which the canonical json (including the data series) can be retrieved. But I suppose someone from the Semantic interoperability Team (@markus.schilling, @bernd.bayerlein, @henkbirkholz) can provide more guidance in this regard
Thanks a lot for your valuable assistance in our infrastructure project. @Bernd diagrams were essential to achieving semantic interoperability. @ya- fan_chen and schaarj, we are delighted to move forward with the PMD Data Acquisition Pipeline. We will update you on our progress and urge you to promptly contact us if we require additional support.
Best regards,
Andre Valdestilhas